上下文膨胀正在掏空你的 AI 工具预算
大多数 AI 编程代理把过多代码塞进上下文窗口,token 成本因此膨胀 5 倍。这篇说明实际代价以及修复方法。
你的 AI 编程代理刚跑完一个任务,消耗了 150,000 token。按 Claude 每 1M 输入 token $0.10 算,这一次 $15。任务只是新增一个 API 端点。
十次里有五次,同样的工作用 30,000 token、$3 就能搞定。
差距不在模型、不在提示词、也不在代理的推理能力。差距在上下文膨胀:喂给 AI 代理远超完成工作所需的代码。大多数团队没察觉这笔税,因为他们把 LLM 成本想成「每 token 一点小费」。但小费会复利。一个团队每天跑 50 个 AI 辅助任务,每个多吃 120,000 个无用 token,每月纯浪费 $18,000。
这不是供应商的问题,是架构问题。可以修。
什么是上下文膨胀?为什么它在烧你的钱?
上下文膨胀发生在 AI 代理为任务取代码时,不理解哪些代码真正重要。代理要给支付模块加一个校验函数。它没拿到支付模块、依赖项、三个相关测试文件,而是拿到 200 个文件:所有带「payment」字样的文件,加上所有语义相似的代码,加上整个文档文件夹——因为向量搜索找到一个边角相关的 README。
代理然后浪费 token 在无关代码里翻找,因为信噪比糟糕做出更差的决策,还得继续追问或重试。你付三次钱:一次为膨胀的上下文,一次为代理在噪声里慢吞吞推理,再一次为返工。
更多 token = 更高的 API 账单
LLM 的成本结构残酷且线性。每一个塞进上下文窗口的 token 都要付钱。按当前 OpenAI 价格,一百万输入 token 约 $5(GPT-4o)。Anthropic 是每百万 $3。一个团队每天在中型代码库上跑 20 个 AI 代理任务,聪明上下文和愚蠢上下文的差距,就是每月 $2,000 与 $10,000 的差距。
上下文膨胀不只发生在大代码库。它发生是因为大多数上下文检索策略很粗暴:关键字搜索、文件路径匹配、或基于嵌入的语义搜索。三种都拉进过多候选。一位工程师在做用户认证,可能因为「user」关键字命中日志、遥测、分析、管理后台。嵌入搜索更糟,把「语义相似」但与实际任务毫不相关的代码也拉进来。
更慢的代理 = 浪费开发者时间
一个起手就带 500 个无关文件的 AI 代理,不只多花 token。它跑得更慢。它在更多噪声里推理。它幻觉更多,因为被无关代码里的矛盾模式搞糊涂。
10 秒的任务变成 30 秒。30 秒的任务变成 2 分钟。对单个等着代理的开发者,两分钟感觉不算什么。但乘上整个团队。如果 5 位工程师每人每天跑 10 个代理任务,每个任务因上下文膨胀延迟 1 分钟,你每天损失 50 个开发者分钟。一年累计 200+ 工程小时盯着加载条。按 $200/小时的全成本算,每位工程师每年损失 $40,000 生产力——按 5 人小组算。
不准确的上下文 = 昂贵的返工
膨胀的上下文导致糟糕的决策。代理被要求「重构这个支付处理函数」,可能看到代码库里三个不同的支付处理函数——一个在遗留单体里,一个在新的微服务里,一个在测试套件里——然后挑错那个。或者它漏掉一个关键依赖,因为相关代码被埋在 500 行无关函数下面。
代理提交修改。代码通过测试(也许)。上线。两周后在生产环境炸了,因为它漏掉某个从未出现在上下文窗口里的模块函数的微妙契约。你花三天调试,再花三天重建。一次修复就是 $40,000 的代价。
量化代价:AI 支出减少 80%
来用一个真实任务。我们做了一个开源基准测试,衡量 AI 代理在一个贴近日常的问题上的表现:给一个真实代码库新增一个 REST API 端点。任务需要理解数据模型、路由层、认证守卫和测试模式。不琐碎,但也不是火箭科学。
基准任务:新增一个 API 端点

这个代码库是典型的 Node.js 后端,150 个文件、25,000 行代码,分布在模型、路由、中间件和测试里。任务:「新增 GET /api/v1/users/:id 端点,按 ID 返回用户并做权限检查。」代理需要改动五个文件:用户模型、路由文件、一个权限中间件、一个测试文件和一个类型文件。
没有依赖图:每次 $15

用朴素的关键字检索(大多数 RAG 系统的默认做法),代理取回 140 个文件。包括所有提到「user」的文件,加上所有带「API」或「endpoint」或「GET」的文件,再加上不相关的测试工具、文档和配置。代理每次消耗 145,000 token。
按 Claude 输入价格:每个任务 $15。
代理还做了 12 次工具调用(读文件、搜代码、跑测试),因为它老是找错文件得反复搜。总耗时 45 秒。
用 Coograph:每次 $3
用代码依赖图——一个理解代码之间真实依赖关系的系统——代理精确取回五个文件:用户模型、路由文件、权限中间件、一个测试文件和类型文件。不猜,不噪声。
代理每次消耗 28,000 token。
成本:每个任务 $3。
代理做了 3 次工具调用,12 秒完成。
差距:便宜 80%、快 4 倍、工具调用减少 4 倍。 在我们可复现的基准测试中,这一结论在多个代码库和任务类型上都成立。
一个每周跑 50 个 AI 辅助任务的团队,每周省下 $600,一年 $31,200,仅 LLM API 成本。再加上找回的开发者时间——每周 50 个任务 × 每个省 33 秒——每周收回 28 小时开发者时间。按 $200/小时算,每周 $5,600 的生产力。
你可以在线查看我们的可复现基准测试。
编程代理里「贪婪」上下文搜索的失败
当今 AI 辅助编程的主导模式是「广撒网、松筛选」。RAG 系统取回 top 50 语义相似的代码片段,寄希望代理的推理能忽略垃圾,然后就这么发车了。
关键字和向量搜索为什么不够
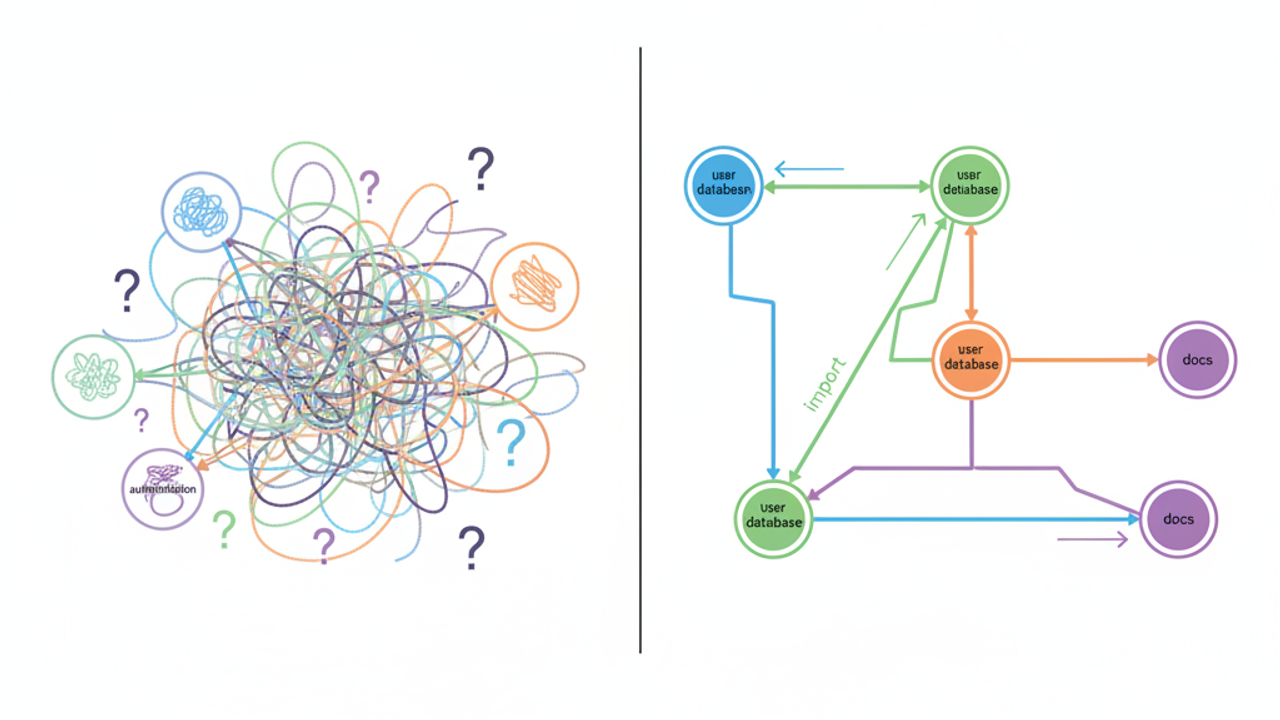
关键字搜索是最简单的失败方式。你搜「authentication」,结果你拿到认证逻辑、认证的测试 mock、提到认证的配置文件、关于认证的文档、以及从未重构的旧死代码。向量嵌入搜索找出感觉上语义相似的代码——「这个函数处理用户身份」和「这个函数查询用户数据库」被归为一类——但它不理解它们在你代码库架构里其实是分开的关注点。
两种方法都不理解你的代码实际上一起做什么。它们是统计游戏,不是结构分析。当你需要精度时,统计游戏注定失败。
失败的代价复利累积。代理拿到混乱上下文。它问澄清问题(更多 token、更多延迟)。它做保守的决定以避免幻觉(更少正确的优化、更少交付价值)。或者它带着信心做错决定、提交损坏的代码,你在生产环境调试。
「凑合」上下文的高昂代价
「凑合」上下文是个陷阱。它感觉便宜,因为 95% 的时候代理拿到错代码也能跑通。但剩下 5% 跑不通时,代价是灾难性的。一次通过单元测试却在生产环境破坏集成的错误重构,已经不是 $3 的问题——是 $40,000 的问题。
即使「跑通」时,膨胀的上下文也在降低代理的表现。一个在 200 个文件里游泳找 5 个相关文件的代理,是在噪声里推理。它变慢。它变得不那么有创意。它把边界情况当作幻觉而不是真实约束。你最终拿到技术上正确但次优的代码,缺少本可在干净上下文里找到的性能改进或更好模式。
代码依赖图如何解决上下文膨胀
解法是停止猜哪些代码重要。改为问你的代码库。代码依赖图是一张地图,描述你的代码实际如何协作——哪个函数调哪个、哪个模块导入哪个、哪些数据结构在哪儿被用。
从猜测到精确
当代理被要求新增一个 API 端点,依赖图让你说:「真正相关的就这五个文件。不多不少。」代理不浪费时间取垃圾。它不会混淆来自无关模块的相似模式。它拿到外科手术级的上下文,能以全速推理。
这不是理论。基准测试结果可复现。在五个不同代码库上(Node.js、Python、Go),结论一致:依赖图上下文比统计检索便宜、快 4-5 倍,并且产生更好的代码质量,因为代理的信噪比更高。
善用团队最有价值的资产:代码本身
人们忽略了这点:你的代码库已经包含「哪些代码对这个任务重要」的答案。代码的结构——导入、函数签名、依赖——是你拥有的最可靠的地图。靠它。
当你接入一个代码图(如果你不熟,可以先了解什么是代码图),你不是加一层魔法 AI。你是利用系统的真实形状。帮助团队理解代码库的同一套结构,也帮 AI 代理。同一种语言:代码。
这就是为什么接入依赖图能跨代码库和任务类型生效。你不是在训练模型或调参。你是把已经存在的信息浮现出来。
上下文优化的自建 vs 采购计算
到这儿,一位多疑的创始人会问:「我们要不要自己造一套依赖图系统?」
自建方案的成本
一位资深工程师从零造代码图引擎(解析、依赖分析、图构建、查询 API),周期是 4-6 个月。算 800-1,200 小时 × $250/小时(强工程师的全成本工资):纯工程成本 $200,000 到 $300,000。再加六周整合到代理框架的工作。你六个月不发布产品。你在解一个基础设施问题。
如果你团队每周跑 50 个 AI 代理任务,每周因上下文膨胀损失 $600,在那个自建周期里累计损失 $30,000。自建的真实成本是 $230,000 到 $330,000。
接入一个开源依赖图
一个为接入设计、MIT 许可的依赖图库,一位工程师一个下午就能插上。你立刻得到精度收益。明天就回到发布产品。
如果你需要企业支持、监控或托管基础设施,Coograph Pro 提供。但开源路径零前期成本,让你在投入预算前先验证 ROI。
想快速上手,文档逐步带你接入。多数团队一天内上线。
这道算术很难反驳。一天买(或接入开源)省 $600/周。或者造六个月,丢掉发布动力,还得花钱。
Coograph 真能在我们的 LLM 账单上省多少?
在我们的基准测试上,Coograph 把 token 消耗砍掉约 80%。一个 AI 代理使用量中等的团队(每周 20-50 个任务),仅 LLM 月省 $2,000–$5,000。再加上找回的开发者时间(代理快 4 倍),ROI 通常一周内转正。
Coograph 会取代 Cursor 或 VS Code Copilot 之类的工具吗?
不会。Coograph 让它们更好。它和现有 AI 代理整合,提供精确、便宜的上下文。你不用改工作流——你正在用的工具会变得更快、更便宜、更准。
是不是只适合大型复杂代码库?
大代码库(100+ 文件)的省钱效果最显著,但速度收益处处可见。精确上下文帮代理避免错误、推理更快,连小项目也能改善产出。团队越小,每一个开发者小时越重要。
实施 Coograph 的工程成本是多少?
开源版采用 MIT 许可,为快速接入而设计。一位开发者通常一个下午能跑通 PoC,一两天内完成生产接入。比自建同类系统快几个数量级。
对闭源代码库或 IP 顾虑怎么处理?
Coograph 完全运行在你的基础设施上——没有代码被送到外部服务器。图在本地基于你的代码库构建,从不离开你的机器。对 IP 或合规要求严格的团队,这是相对云端方案的关键优势。
如果你团队在跑 AI 代理而 LLM 账单一直爬升,上下文膨胀很可能就是元凶。修复不是更好的提示词或更聪明的代理——是精确的上下文。先看 Coograph 立即开始体会接入有多快,或如果你想要内建的企业支持和监控,看看 Coograph Pro。你的下一次成本下降,可能就只差一天工程。
削减你的 AI 编程账单 30–80%。Coograph 采用 MIT 许可、永久免费。Pro 提供定制服务。