上下文膨脹正在掏空你的 AI 工具預算
大多數 AI 編程代理把過多程式碼塞進上下文視窗,token 成本因此膨脹 5 倍。這篇說明實際代價以及修復方法。
你的 AI 編程代理剛跑完一個任務,消耗了 150,000 token。按 Claude 每 1M 輸入 token $0.10 算,這一次 $15。任務只是新增一個 API 端點。
十次裡有五次,同樣的工作用 30,000 token、$3 就能搞定。
差距不在模型、不在提示詞、也不在代理的推理能力。差距在上下文膨脹:餵給 AI 代理遠超完成工作所需的程式碼。大多數團隊沒察覺這筆稅,因為他們把 LLM 成本想成「每 token 一點小費」。但小費會複利。一個團隊每天跑 50 個 AI 輔助任務,每個多吃 120,000 個無用 token,每月純浪費 $18,000。
這不是供應商的問題,是架構問題。可以修。
什麼是上下文膨脹?為什麼它在燒你的錢?
上下文膨脹發生在 AI 代理為任務取程式碼時,不理解哪些程式碼真正重要。代理要給支付模組加一個校驗函式。它沒拿到支付模組、依賴項、三個相關測試檔案,而是拿到 200 個檔案:所有帶「payment」字樣的檔案,加上所有語義相似的程式碼,加上整個文件資料夾——因為向量搜尋找到一個邊角相關的 README。
代理然後浪費 token 在無關程式碼裡翻找,因為信噪比糟糕做出更差的決策,還得繼續追問或重試。你付三次錢:一次為膨脹的上下文,一次為代理在噪音裡慢吞吞推理,再一次為返工。
更多 token = 更高的 API 帳單
LLM 的成本結構殘酷且線性。每一個塞進上下文視窗的 token 都要付錢。按當前 OpenAI 價格,一百萬輸入 token 約 $5(GPT-4o)。Anthropic 是每百萬 $3。一個團隊每天在中型程式碼庫上跑 20 個 AI 代理任務,聰明上下文和愚蠢上下文的差距,就是每月 $2,000 與 $10,000 的差距。
上下文膨脹不只發生在大程式碼庫。它發生是因為大多數上下文檢索策略很粗暴:關鍵字搜尋、檔案路徑匹配、或基於嵌入的語義搜尋。三種都拉進過多候選。一位工程師在做使用者認證,可能因為「user」關鍵字命中日誌、遙測、分析、管理後台。嵌入搜尋更糟,把「語義相似」但與實際任務毫不相關的程式碼也拉進來。
更慢的代理 = 浪費開發者時間
一個起手就帶 500 個無關檔案的 AI 代理,不只多花 token。它跑得更慢。它在更多噪音裡推理。它幻覺更多,因為被無關程式碼裡的矛盾模式搞糊塗。
10 秒的任務變成 30 秒。30 秒的任務變成 2 分鐘。對單個等著代理的開發者,兩分鐘感覺不算什麼。但乘上整個團隊。如果 5 位工程師每人每天跑 10 個代理任務,每個任務因上下文膨脹延遲 1 分鐘,你每天損失 50 個開發者分鐘。一年累計 200+ 工程小時盯著載入條。按 $200/小時的全成本算,每位工程師每年損失 $40,000 生產力——按 5 人小組算。
不準確的上下文 = 昂貴的返工
膨脹的上下文導致糟糕的決策。代理被要求「重構這個支付處理函式」,可能看到程式碼庫裡三個不同的支付處理函式——一個在遺留單體裡,一個在新的微服務裡,一個在測試套件裡——然後挑錯那個。或者它漏掉一個關鍵依賴,因為相關程式碼被埋在 500 行無關函式下面。
代理提交修改。程式碼通過測試(也許)。上線。兩週後在生產環境炸了,因為它漏掉某個從未出現在上下文視窗裡的模組函式的微妙契約。你花三天除錯,再花三天重建。一次修復就是 $40,000 的代價。
量化代價:AI 支出減少 80%
來用一個真實任務。我們做了一個開源基準測試,衡量 AI 代理在一個貼近日常的問題上的表現:給一個真實程式碼庫新增一個 REST API 端點。任務需要理解資料模型、路由層、認證守衛和測試模式。不瑣碎,但也不是火箭科學。
基準任務:新增一個 API 端點

這個程式碼庫是典型的 Node.js 後端,150 個檔案、25,000 行程式碼,分布在模型、路由、中介軟體和測試裡。任務:「新增 GET /api/v1/users/:id 端點,按 ID 回傳使用者並做權限檢查。」代理需要改動五個檔案:使用者模型、路由檔案、一個權限中介軟體、一個測試檔案和一個型別檔案。
沒有依賴圖:每次 $15

用樸素的關鍵字檢索(大多數 RAG 系統的預設做法),代理取回 140 個檔案。包括所有提到「user」的檔案,加上所有帶「API」或「endpoint」或「GET」的檔案,再加上不相關的測試工具、文件和設定。代理每次消耗 145,000 token。
按 Claude 輸入價格:每個任務 $15。
代理還做了 12 次工具呼叫(讀檔、搜程式碼、跑測試),因為它老是找錯檔案得反覆搜。總耗時 45 秒。
用 Coograph:每次 $3
用程式碼依賴圖——一個理解程式碼之間真實依賴關係的系統——代理精確取回五個檔案:使用者模型、路由檔案、權限中介軟體、一個測試檔案和型別檔案。不猜,不噪音。
代理每次消耗 28,000 token。
成本:每個任務 $3。
代理做了 3 次工具呼叫,12 秒完成。
差距:便宜 80%、快 4 倍、工具呼叫減少 4 倍。 在我們可重現的基準測試中,這一結論在多個程式碼庫和任務類型上都成立。
一個每週跑 50 個 AI 輔助任務的團隊,每週省下 $600,一年 $31,200,僅 LLM API 成本。再加上找回的開發者時間——每週 50 個任務 × 每個省 33 秒——每週收回 28 小時開發者時間。按 $200/小時算,每週 $5,600 的生產力。
你可以線上查看我們的可重現基準測試。
編程代理裡「貪婪」上下文搜尋的失敗
當今 AI 輔助編程的主導模式是「廣撒網、鬆篩選」。RAG 系統取回 top 50 語義相似的程式碼片段,寄希望代理的推理能忽略垃圾,然後就這麼發車了。
關鍵字和向量搜尋為什麼不夠
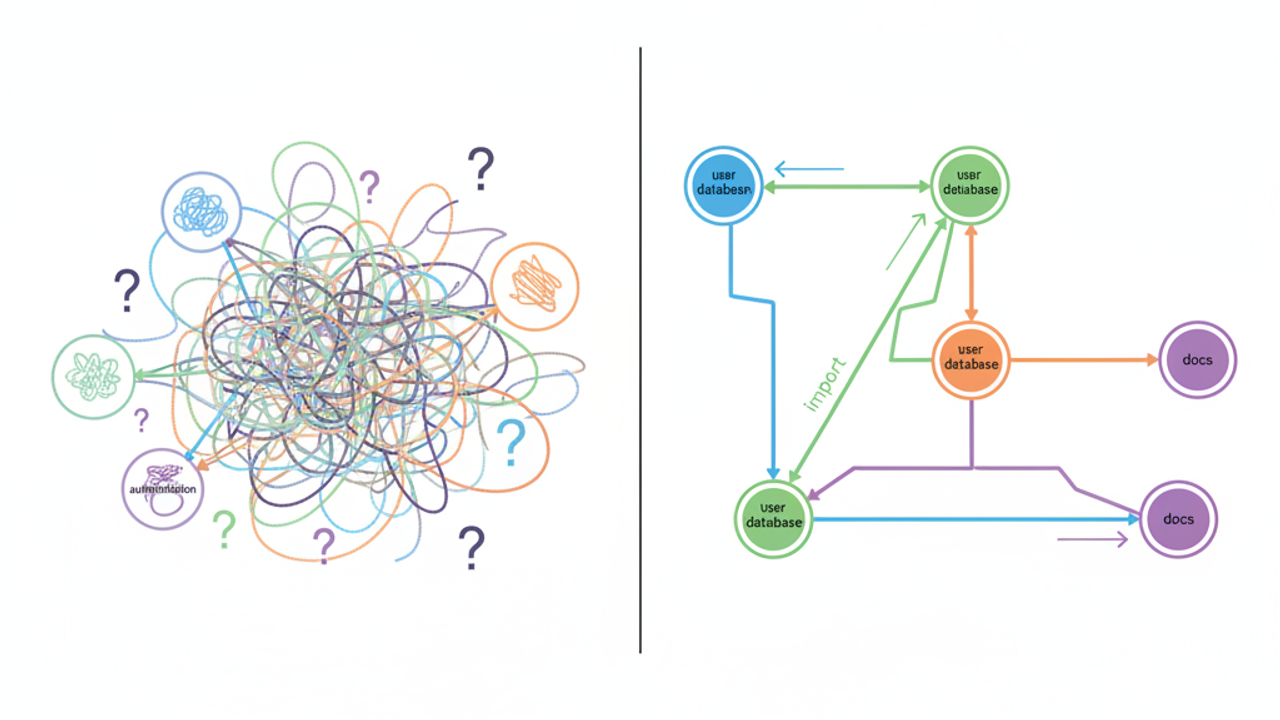
關鍵字搜尋是最簡單的失敗方式。你搜「authentication」,結果你拿到認證邏輯、認證的測試 mock、提到認證的設定檔、關於認證的文件、以及從未重構的舊死程式碼。向量嵌入搜尋找出感覺上語義相似的程式碼——「這個函式處理使用者身份」和「這個函式查詢使用者資料庫」被歸為一類——但它不理解它們在你程式碼庫架構裡其實是分開的關注點。
兩種方法都不理解你的程式碼實際上一起做什麼。它們是統計遊戲,不是結構分析。當你需要精度時,統計遊戲注定失敗。
失敗的代價複利累積。代理拿到混亂上下文。它問澄清問題(更多 token、更多延遲)。它做保守的決定以避免幻覺(更少正確的最佳化、更少交付價值)。或者它帶著信心做錯決定、提交損壞的程式碼,你在生產環境除錯。
「湊合」上下文的高昂代價
「湊合」上下文是個陷阱。它感覺便宜,因為 95% 的時候代理拿到錯程式碼也能跑通。但剩下 5% 跑不通時,代價是災難性的。一次通過單元測試卻在生產環境破壞整合的錯誤重構,已經不是 $3 的問題——是 $40,000 的問題。
即使「跑通」時,膨脹的上下文也在降低代理的表現。一個在 200 個檔案裡游泳找 5 個相關檔案的代理,是在噪音裡推理。它變慢。它變得不那麼有創意。它把邊界情況當作幻覺而不是真實約束。你最終拿到技術上正確但次優的程式碼,缺少本可在乾淨上下文裡找到的效能改進或更好模式。
程式碼依賴圖如何解決上下文膨脹
解法是停止猜哪些程式碼重要。改為問你的程式碼庫。程式碼依賴圖是一張地圖,描述你的程式碼實際如何協作——哪個函式呼叫哪個、哪個模組匯入哪個、哪些資料結構在哪兒被用。
從猜測到精確
當代理被要求新增一個 API 端點,依賴圖讓你說:「真正相關的就這五個檔案。不多不少。」代理不浪費時間取垃圾。它不會混淆來自無關模組的相似模式。它拿到外科手術級的上下文,能以全速推理。
這不是理論。基準測試結果可重現。在五個不同程式碼庫上(Node.js、Python、Go),結論一致:依賴圖上下文比統計檢索便宜、快 4-5 倍,並且產生更好的程式碼品質,因為代理的信噪比更高。
善用團隊最有價值的資產:程式碼本身
人們忽略了這點:你的程式碼庫已經包含「哪些程式碼對這個任務重要」的答案。程式碼的結構——匯入、函式簽章、依賴——是你擁有的最可靠的地圖。靠它。
當你接入一個程式碼圖(如果你不熟,可以先了解什麼是程式碼圖),你不是加一層魔法 AI。你是利用系統的真實形狀。幫助團隊理解程式碼庫的同一套結構,也幫 AI 代理。同一種語言:程式碼。
這就是為什麼接入依賴圖能跨程式碼庫和任務類型生效。你不是在訓練模型或調參。你是把已經存在的資訊浮現出來。
上下文最佳化的自建 vs 採購計算
到這兒,一位多疑的創辦人會問:「我們要不要自己造一套依賴圖系統?」
自建方案的成本
一位資深工程師從零造程式碼圖引擎(解析、依賴分析、圖建構、查詢 API),週期是 4-6 個月。算 800-1,200 小時 × $250/小時(強工程師的全成本薪資):純工程成本 $200,000 到 $300,000。再加六週整合到代理框架的工作。你六個月不發布產品。你在解一個基礎設施問題。
如果你團隊每週跑 50 個 AI 代理任務,每週因上下文膨脹損失 $600,在那個自建週期裡累計損失 $30,000。自建的真實成本是 $230,000 到 $330,000。
接入一個開源依賴圖
一個為接入設計、MIT 授權的依賴圖庫,一位工程師一個下午就能插上。你立刻得到精度收益。明天就回到發布產品。
如果你需要企業支援、監控或託管基礎設施,Coograph Pro 提供。但開源路徑零前期成本,讓你在投入預算前先驗證 ROI。
想快速上手,文件逐步帶你接入。多數團隊一天內上線。
這道算術很難反駁。一天買(或接入開源)省 $600/週。或者造六個月,丟掉發布動力,還得花錢。
Coograph 真能在我們的 LLM 帳單上省多少?
在我們的基準測試上,Coograph 把 token 消耗砍掉約 80%。一個 AI 代理使用量中等的團隊(每週 20-50 個任務),僅 LLM 月省 $2,000–$5,000。再加上找回的開發者時間(代理快 4 倍),ROI 通常一週內轉正。
Coograph 會取代 Cursor 或 VS Code Copilot 之類的工具嗎?
不會。Coograph 讓它們更好。它和現有 AI 代理整合,提供精確、便宜的上下文。你不用改工作流——你正在用的工具會變得更快、更便宜、更準。
是不是只適合大型複雜程式碼庫?
大程式碼庫(100+ 檔案)的省錢效果最顯著,但速度收益處處可見。精確上下文幫代理避免錯誤、推理更快,連小專案也能改善產出。團隊越小,每一個開發者小時越重要。
實施 Coograph 的工程成本是多少?
開源版採用 MIT 授權,為快速接入而設計。一位開發者通常一個下午能跑通 PoC,一兩天內完成生產接入。比自建同類系統快幾個數量級。
對閉源程式碼庫或 IP 顧慮怎麼處理?
Coograph 完全執行在你的基礎設施上——沒有程式碼被送到外部伺服器。圖在本地基於你的程式碼庫建構,從不離開你的機器。對 IP 或合規要求嚴格的團隊,這是相對雲端方案的關鍵優勢。
如果你團隊在跑 AI 代理而 LLM 帳單一直爬升,上下文膨脹很可能就是元凶。修復不是更好的提示詞或更聰明的代理——是精確的上下文。先看 Coograph 立即開始體會接入有多快,或如果你想要內建的企業支援和監控,看看 Coograph Pro。你的下一次成本下降,可能就只差一天工程。
削減你的 AI 編程帳單 30–80%。Coograph 採用 MIT 授權、永久免費。Pro 提供客製服務。